confidential-computing The Privacy Paradox: Why AI Teams Should Care About Confidential Computing
Jilks Smith
· 9 min read

As organizations race to integrate Large Language Models into their operations, they’re simultaneously exposing intellectual property, customer records, financial models and many more assets to unprecedented vulnerabilities. The problem? Traditional software architectures are structurally inadequate for the AI era.
The Data-in-Use Gap
For decades, cybersecurity has relied on protecting data at rest (disk encryption) and data in transit (TLS). This framework has been largely successful—until now.
The critical gap is data in use. To generate value, data must be decrypted and loaded into memory for processing. At this moment, data exists in plaintext, vulnerable to:
- Operating system access
- Hypervisor inspection
- Cloud administrator snooping
- Malicious actors with privileged access
In the pre-AI era, this vulnerability was manageable because the exposure window was small. With AI this risk profile changes.
The AI Multiplier Effect
Training or running inference on LLMs requires loading massive datasets into memory for extended periods. The “context window” of an LLM becomes a “vulnerability window.”
If an attacker gains access, the entire contents of memory are available for exfiltration in cleartext. The models themselves have become high-value assets worth hundreds of millions in R&D investment.
This creates a paradox: organizations must use cloud scale to train models, but cannot trust the cloud with secrets and sensitive data.
Real-World Breach Forensics
The fragility of AI data pipelines isn’t theoretical. Recent incidents demonstrate the urgent need for architectural change.
Microsoft AI Research Exposure (2023)
Microsoft’s AI research team accidentally exposed 38 terabytes of private data while publishing open-source training data on GitHub. The breach included:
- Disk backups of employee workstations
- Private keys and passwords
- Over 30,000 internal Teams messages
The Lesson: AI “data lakes” are massive targets. While this was a storage misconfiguration, it highlights the risk of aggregated plaintext data. Cube AI mitigates this by keeping data encrypted even during processing. Even if storage keys are leaked, attackers cannot decrypt the data without the hardware-bound keys held securely inside the TEE.
Change Healthcare Ransomware (2024)
The February 2024 attack on Change Healthcare paralyzed the US healthcare system, costing over $872 million and disrupting patient care nationwide. Attackers gained entry via compromised credentials and allegedly stole 6TB of sensitive medical data.
The Lesson: Credential theft shouldn’t mean data compromise. Cube AI ensures that even if an attacker gains root access to the server, they cannot read patient data from memory. Its automated attestation checks would detect the presence of unauthorized ransomware code and refuse to release the decryption keys, effectively neutralizing the attack.
Samsung ChatGPT Leak (2023)
Engineers leaked proprietary source code and meeting notes into ChatGPT, demonstrating how “Shadow AI” bypasses IT governance. Once data enters the “AI black box,” organizations lose visibility and control.
The Lesson: Without architectural safeguards like Confidential Computing, sensitive data can flow into uncontrolled environments with no audit trail or protection.
AI-Specific Attack Vectors
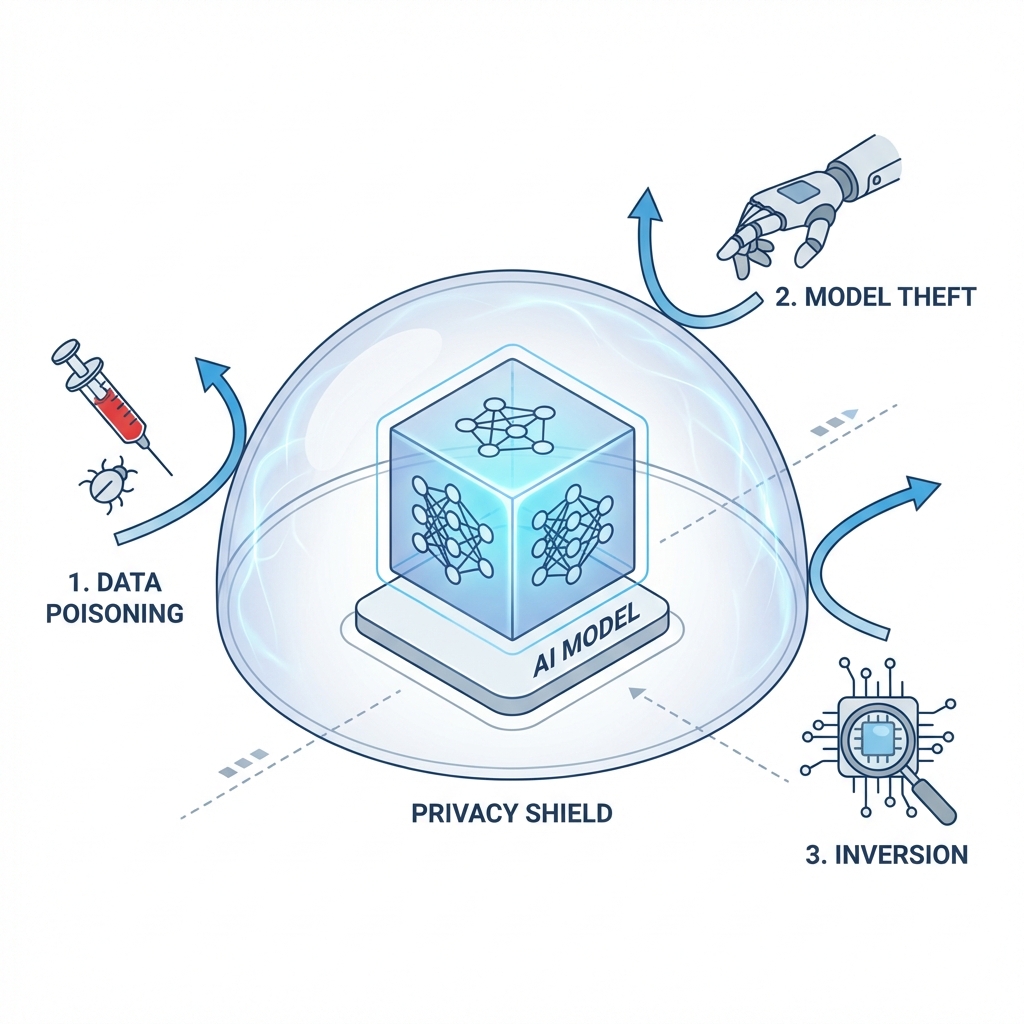
Beyond traditional breaches, AI systems face unique adversarial attacks:
Model Inversion & Membership Inference
Attackers can query API-exposed models to reconstruct training data. “Model Inversion” recreates specific training examples (faces, patient records). “Membership Inference” determines if specific data was used in training.
The Cube AI Solution: Cube AI runs inference inside tamper-proof enclaves, ensuring that privacy controls cannot be disabled by malicious admins or compromised infrastructure.
Model Theft
For AI companies, model weights are primary IP. In standard cloud deployments, weights reside in GPU memory. Sophisticated attackers with kernel access can copy these weights.
The Cube AI Solution: Cube AI protects your proprietary model weights from being dumped or stolen, even by the cloud provider hosting the hardware.
The Regulatory Imperative
Global regulations are accelerating Confidential Computing adoption, moving from general data protection to specific AI safety mandates.
EU AI Act
The world’s first comprehensive AI law includes provisions that directly align with Confidential Computing capabilities:
- Article 78 (Confidentiality): Mandates protection of intellectual property and trade secrets
- Article 15 (Cybersecurity): Requires high-risk AI systems to resist unauthorized alteration—implying execution environments that guarantee code and data integrity (TEEs)
- Article 10 (Data Governance): Mandates data integrity and confidentiality during processing
US Legislation
By 2025, all 50 states introduced AI-related legislation. States like Colorado and California regulate algorithmic discrimination and require risk management policies, driving demand for auditable, secure compute environments.
Federal Executive Orders emphasize securing the AI supply chain and preventing model theft by adversaries—goals directly supported by hardware-enforced isolation.
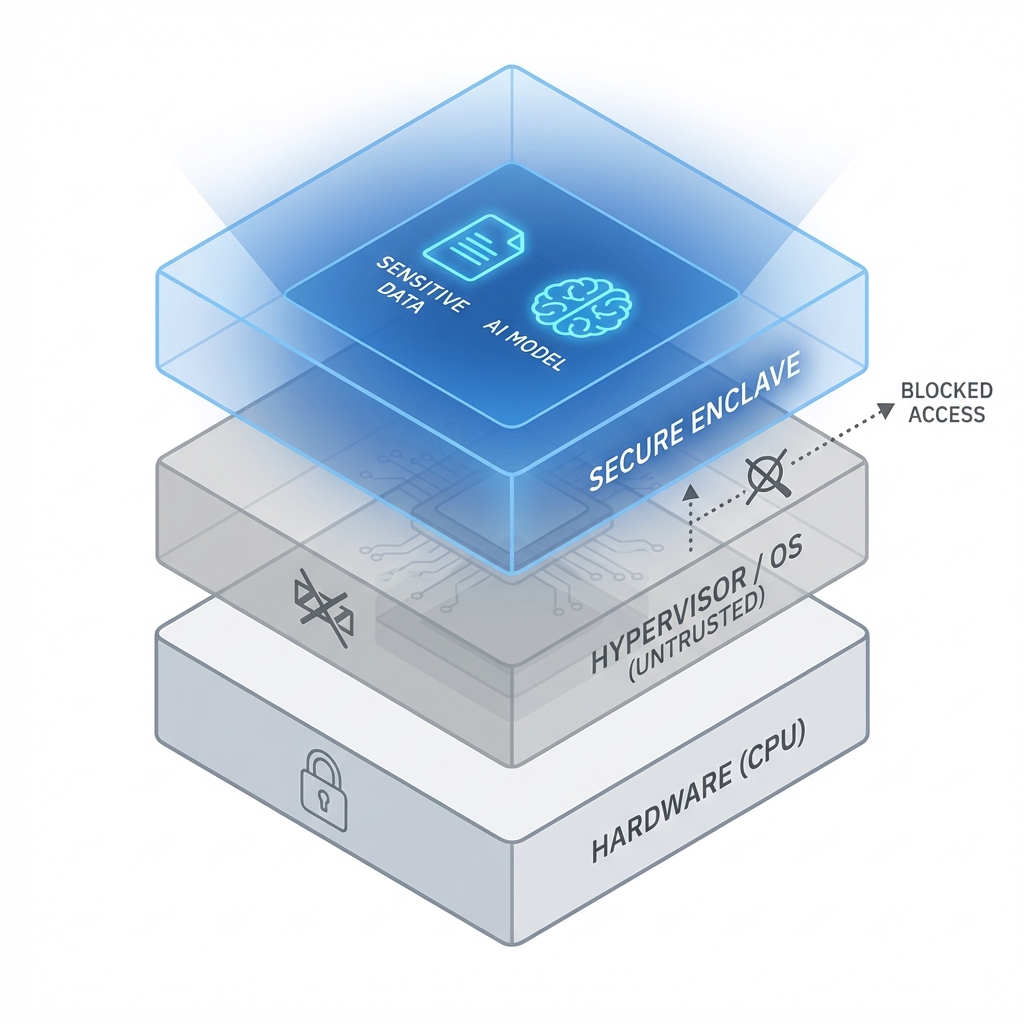
How Confidential Computing Works
Confidential Computing resolves the Privacy Paradox by changing the fundamental assumption of trust in the compute stack.
Trusted Execution Environments (TEEs)
TEEs are hardware-isolated environments where code and data are protected from the rest of the system:
- Memory Encryption: Data written to RAM is encrypted with keys generated inside the CPU package that never leave it
- Access Control: CPUs prevent any software outside the TEE (OS, hypervisor, other VMs) from reading or writing TEE memory
- Attestation: Cryptographic proof that specific code is running in a genuine, untampered TEE
Even with full root privileges, attackers see only encrypted ciphertext when attempting to access TEE memory.
Hardware Platforms
AMD SEV-SNP: Each VM gets a unique memory encryption key. Ideal for confidential VMs hosting AI control planes, vector databases, or CPU-based inference.
Intel TDX: Introduces “Trust Domains” with efficient memory encryption. Optimized for high-performance compute and rigorous attestation. Strong for sensitive model training pipelines.
NVIDIA H100 Confidential GPU: Revolutionary for AI. Encrypts GPU memory (up to 80GB HBM3) and the CPU-GPU link. Enables confidential training and inference with little overhead for compute-bound workloads.
Remote Attestation
Remote attestation proves a workload is running in a genuine TEE:
- Measurement: Hardware computes a cryptographic hash of code loaded into the TEE
- Evidence Generation: Hardware signs this hash with a private key embedded in silicon
- Verification: An Attestation Service checks the signature against manufacturer public keys
- Key Release: If verification succeeds, decryption keys are released to the workload
This ensures keys are never released unless the environment is proven secure and untampered. If malware is injected, the hash changes, verification fails, and keys remain locked.
Industry Applications
Healthcare: Clinical AI Development
Challenge: Developing clinical AI requires diverse patient data, but privacy regulations create friction. Traditional de-identification is costly, slow, and reduces data fidelity.
How Confidential Computing Helps: Secure enclaves enable a data escrow model where hospitals encrypt data and upload to TEEs. Algorithm developers upload models to the same enclave. Models execute against data inside the TEE—developers receive performance reports but never access raw data.
Potential Benefits:
- Reduced time-to-insight from months to days
- Lower costs by avoiding synthetic data purchases and extensive legal review
- Access to rare disease datasets previously inaccessible due to privacy fragmentation
Financial Services: Anti-Money Laundering
Challenge: AML efforts are hampered by information silos. Banks only see transactions within their walls. Criminals exploit this by moving funds across institutions. Traditional systems generate high false positive rates (often exceeding 90%).
How Confidential Computing Helps: Federated Learning in secure enclaves allows models to move to banks’ secure environments, learn from local data without data leaving custody, then aggregate to form more accurate global detectors.
Potential Benefits:
- Significant reduction in false positive rates
- Improved detection accuracy across institutions
- Ability to identify cross-institutional money laundering patterns
Implementation Strategies: Build vs. Buy
Organizations generally face two paths when adopting Confidential Computing:
Option 1: The Hard Way (Raw Infrastructure)
You can build directly on top of raw Confidential VMs (CVMs) or Confidential Containers (CoCo).
Confidential VMs (CVMs)
- Approach: “Lift and Shift”—run entire VMs inside TEEs (AMD SEV-SNP).
- Pros: Works with legacy applications.
- Cons: Large Trusted Computing Base (TCB); you are responsible for managing attestation and key exchanges.
Confidential Containers (CoCo)
- Approach: Run Kubernetes Pods in lightweight microVM TEEs.
- Pros: Smaller TCB and better isolation.
- Cons: Requires complex Kubernetes setup and deep expertise in attestation flows.
Option 2: The Smart Way (Cube AI Platform)
The alternative is to use a platform that abstracts this complexity. Cube AI bridges the gap, offering the security of Option 1 with the usability of a standard cloud service.
1. Zero-Refactor Integration Cube AI provides an OpenAI-compatible API, meaning you can switch your existing applications to run on confidential infrastructure without rewriting a single line of code.
2. Infrastructure as a Plugin As detailed in our comparison of vLLM and Ollama, Cube AI treats the inference engine as a swappable plugin. You can toggle between cost-effective local models (Ollama) and high-performance GPU models (vLLM) without changing your security posture.
3. Automated Security & Compliance Cube AI handles the heavy lifting of Confidential Computing:
- Attested TLS (aTLS): Automatically terminates connections inside the enclave.
- Built-in Guardrails: Enforces data policies before requests reach the model, preventing PII leakage.
By solving the “usability paradox,” Cube AI allows organizations to protect their data immediately, rather than spending months building custom security infrastructure.
The Path Forward
The global confidential computing market is projected to grow from $9.04 billion in 2024 to over $1,281 billion by 2034—a 64% CAGR. This isn’t just security spending; it’s a structural transformation in enterprise computing architecture.
By 2026, over 70% of enterprise AI workloads will involve sensitive data, making confidential architectures a necessity rather than a luxury.
The HTTPS Moment
In internet history, there was a moment when HTTPS transitioned from a requirement for banking sites to the default standard for the entire web. We’re at that same inflection point for AI.
Confidential Computing is the “HTTPS for AI”—the protocol that builds the trust necessary for the next generation of intelligent systems to flourish.
Key Takeaways
- Traditional security fails AI: The “two-state” model (at rest, in transit) leaves data-in-use vulnerable—the exact state AI requires
- Hardware-based isolation is essential: TEEs provide mathematical guarantees that software-based security cannot
- Regulatory pressure is accelerating: The EU AI Act and US legislation increasingly demand “privacy by design” 4The question has changed: From “Can we afford to implement this?” to “Can we survive ignoring it?”
Ready to secure your AI workloads? Learn more about Cube AI’s confidential computing architecture or explore our developer guides to get started.